国家知识产权局专利局专利审查协作河南中心,河南 郑州 450000
摘要:本文介绍了关联规则相关的重要技术及其技术发展路线,通过对关联规则相关专利进行分析,梳理出关联规则推荐技术重要的发展及趋势,并结合业内重要申请人的技术演进,对推荐系统的发展历程和呈现形态进行分析,预测未来关联规则推荐系统技术的发展新趋势。
关联规则是数据挖掘领域的重要算法,其广泛应用于各个领域,其优点在于关联规则反映了事物之间的相互依赖性和关联性,关联规则技术则是将数据资料中产生的高关联性项目组进行收集处理,然后构建起一定的关联规则。构建出的关联规则必须满足用户规定的最小支持度,它表示了一组项目关联在一起需要满足的最低联系程度。构建出的关联规则也必须满足用户规定的最小可信度,它反映了一个关联规则的最低可靠度。
目前常用的基于关联规则的推荐算法有以下三种:Apriori算法,FP-Tree算法和Eclat算法。上述算法都是基于关联规则的算法,其算法也都由频繁项发现和产生关联规则两部分组成,对算法的优化也都是基于上述两部分进行的。
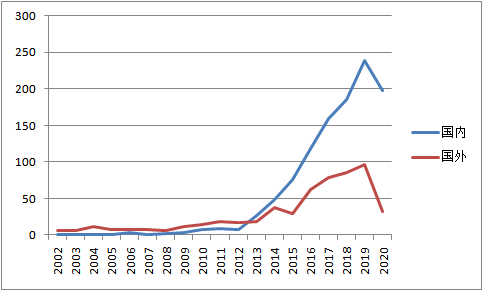
图1 国内外专利申请量历年分布图
由图1可以看出,基于关联规则的推荐的中国专利申请量基本与全球申请量趋势保持一致,基本上保持逐步增长的态势,在2015年之后与全球申请量一样进入急速增长阶段。基于关联规则的推荐的中国专利申请相比于全球起步较晚,第一件专利申请出现在2003年,而外国的最早的相关申请出现在1995年。这主要原因是由于国内申请人的基础研究能力薄弱,并且国内的个性化推荐的市场比较小,国外申请人对中国市场不够重视。2012年之后,随着大数据技术的发展和中国经济的增长,国内申请人的专利申请量开始快速增长,并在2013年超过了国外申请人的申请量,在接下来的几年中,国内申请人的申请量也远远超过了国外申请人,这与中国大力推动互联网建设密切相关。
从全球专利申请量排名前10位的申请人来看,主要来自中国、美国和俄罗斯。其中中国企业和机构占据7个席位,美国企业有2个席位,俄罗斯有1个席位。从企业类型来看,IBM、国家电网、腾讯、阿里巴巴、京东、Yandex,Tata、微软、平安都是各国知名的涉及大数据的企业,占据了9个席位,重庆邮电大学作为知名高校占据了1个席位。由上可见,涉及大数据业务的企业是推动基于关联规则推荐技术的中的主要力量。
目前常用的基于关联规则的推荐算法有以下三种:Apriori算法,FP-Tree算法和Eclat算法。上述算法都是基于关联规则的算法,其算法也都由频繁项发现和产生关联规则两部分组成,对算法的优化也都是基于上述两部分进行的。
Apriori算法是挖掘关联规则频繁项集的典型算法,其核心思想是基于两个阶段频繁集的递推。首先基于先验知识设定最小支持度和最小置信度,通过扫描事件集找出所有的频繁项集,在此基础上找出频繁二项集,如此迭代找出满足最小支持度的所有频繁集,由频繁集产生强关联规则,然后使用前面找到的频繁集产生满足最小置信度的强规则,从而推荐出用户感兴趣的事件。
(1)理论创建和完善:在这个时期Apriori算法刚刚被提出时,相关的专利申请量较少,对Apriori算法的研究主要在于创立和完善具体的算法。IBM在1995年5月提出了申请号为US43679495A的专利,其公开了如何发现频繁项,定义了如何在消费者的购买记录中发现交易关联频繁项的方法。
(2)算法的优化:随着大数据和互联网技术的发展,数据量呈现爆炸式的增长,Apriori算法的缺点日益突出,其在数据集较大的情况下效率比较慢,因此对Apriori算法进行优化是关注的重点,IBM在2011年8月申请号为US13206827中通过数据挖掘算法将处理所有列以及所有列组合和列查找列模式时,以优化和改进以提高频繁项的发现效率。
算法与其他算法或具体领域相结合:随着市场对于个性化推荐的要求的日益提高,各个领域的企业纷纷开始在该领域进行大量专利布局,因此,Apriori算法与具体的技术领域相结合,进而对Apriori算法根据领域的特点进行优化成为了研究热点。阿里巴巴在2016年3月申请号为CN201610200506中提出了一种频繁项集的挖掘方法、装置及系统,利用频繁项集挖掘算法对被分配的子数据进行频繁项集挖掘,得到局部频繁项集以提升数据项挖掘的耗费时间。
在2000年由Han Jiawei等人提出的FP-GROWTH算法为了提高挖掘效率,减少对原数据集的读取次数及候选频繁项目集的生成,要求在内存中构造FP-TREE。 FP-TREE以共享前缀的方式对原始数据集进行了极大的压缩。
理论创建和完善:在FP-tree算法刚刚被提出时,主要的研究方式完善FP-tree基础算法。HAN JIAWEI在2003年02月申请号为US74601200中提出了一种本发明提供了可用于为频繁项目挖掘数据库的方法装置和数据结构。有助于数据挖掘的方式使用频繁模式树来表示数据库的内容。
(2)算法的优化:在这个阶段,随着数据量的增加,但研究还是集中在算法的改进,申请人主要集中在外国大公司和科研院所。英特尔公司在2009年5月提出了申请号为CN200680054391用于基于内容的分割与挖掘的基于系统的方法,公开了提供用于将数据库或数据仓的数据分割为几个独立部分而作为数据挖掘过程的组成部分的方法和系统。
(3)算法与其他算法或具体领域相结合:随着个性化推荐的迅速发展,FP-tree技术也迎来了爆发式的增长,其应用于商品推荐,服务推荐等众多领域,电子科技大学在2018年12月申请号为CN201810786269中提出了基于学生数据的行为趋势挖掘分析方法和系统,本发明提出了一种随机森林权重自拟合算法,在对非均衡数据的分类上能够提高少数类的准确率,同时能够适应随着时间推移数据分布以及行为表现上的变化。
Eclat算法是Zaki等人提出的一种基于垂直数据结构表示,运用深度优先搜索策略进行关联规则挖掘的算法。该算法利用等价类思想将事务数据库划分为相互不重叠的多个独立子空间,每个子空间自底向上独立进行挖掘。
(1)理论创建和完善:在Eclat算法刚刚被提出时,Eclat算法刚刚被提出,该阶段的重点在于算法理论的创建和完善。为了寻找网络中的最佳路径,ORACLE在1998年05月在申请号为US7355898中提出了一种受外界影响的接近最优路径装置和方法受外界影响的接近最优路径装置和方法,其中详细介绍了等价类的概念。
(2)算法的优化:在这个阶段,随着数据量的增加,但研究还是集中在算法的改进,申请人主要集中在外国大公司和科研院所。IBM在2016年3月在申请号为US201715613404中提出了在多个运行时产物中搜索至少一个关系模式的方法和系统,公开了如何在SQL数据库中发现最频繁使用的SQL关系以便提高频繁项的发现效率和准确度。
(3)算法与其他算法或具体领域相结合:随着市场对于个性化推荐的要求的日益提高,各个领域的企业纷纷开始在该领域进行大量专利布局,因此,Eclat算法与具体的技术领域相结合,进而对Eclat算法根据领域的特点进行优化成为了研究热点,腾讯在2019年6月申请号为CN201910517806中提出了一种热点挖掘方法,利用所述文档簇之间的相似性进行文档簇聚类,得到目标文档簇以过滤掉大量未包含频繁项集的文档,为后续层次聚类节省时间开销,提高了热点挖掘效率。
随着大数据时代的来临,对大数据进行数据挖掘以获得有用的信息以进行个性化推荐势必成为产业研究的热点,而基于关联规则的推荐作为常用的个性化推荐方式之一也成为研究和关注的重点。Apriori算法是目前使用的最广泛的基于关联规则推荐的算法,国内和国外均对其进行了广泛的研究和应用,在国内以电子商务为代表的企业,例如,阿里巴巴,腾讯,京东等对在这方面具备较强的技术实力,因此,上述企业可以针对Ariori算法继续进行研究和相关专利申请,完善其在国内和国外的专利布局。FP-Tree算法和Eclat算法的改进和应用仍有较大的研究和申请空间,可以针对这两种算法进行针对性的布局和改进。(作者1对本文贡献等同于第一作者。)

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



