南京审计大学
【项目信息】:本文受南京审计大学2020年度大学生创新创业训练计划资助,项目编号:2020SX07008Q
摘要:人工智能时代,大数据算法自动化决策在生活中的应用渐趋广泛。同时算法权利的滥用所带来的信息安全隐患和信息茧房效应也显现出来,如何在利用好算法自动化决策带来的便利的同时,规范相关行业的算法权利保护用户的信息使用知情权等,为此本团队以短视频APP为例探讨研究了人工智能时代算法自动化决策的风险法律治理。
关键词:算法自动化、信息安全、法律治理、短视频APP
随着人工智能的不断发展和应用,大数据和算法相关技术的发展也为流量时代的发展提供着越来越多的便利。算法自动化决策在日常中的应用,一方面体现在使用各类APP的兴趣推荐、同城热点,另一方面则是无形的,更加契合用户个人特点的自身看不到的产物——用户画像,用户画像产生的依据便是APP利用各类权限取得的个人信息,包括浏览记录、地域特征、年龄等等。但是由于相关法律管理的不到位,经营者滥用大数据算法权利,利用权限使用过多的个人信息,甚至存在买卖用户隐私的行为,比如工信部披露的各类侵犯用户权益的APP(2020年搜狐旗下的“狐友”私自收集个人信息、“去哪儿网”账号注销难度大等),据不完全统计有58款相类似APP强制要求获取权限、超范围收集个人信息、私自将信息共享给第三方......这些行为给APP使用者的隐私安全带来了巨大的风险。由此,算法自动化决策的法律治理有需要且有必要。自大数据时代产生、发展以来,相关领域的学术研究有很多,而必要的法律治理、规章制度却未能跟进算法自动化涉及的隐私安全等方面问题的管理。滥用算法权利的背后,是缺乏统一的行业标准、法规和权利红线。该项目的研究意义即在于为当下人工智能时代算法自动化决策方面存在的问题提出法律治理的相关意见,以保护用户的网络隐私安全、进一步减少互联网信息买卖现象。由此我们调查整理并讨论研究了人工智能时代算法自动化决策风险法律治理。
一、算法自动化决策的运行机制
算法指的是对于解决问题方案的准确、清晰的描述,是被计算机所使用的,一系列能够帮助解决问题的指令。而在人工智能的时代背景下,算法自动化决策指的就是计算机通过算法的演算,得出用户对于信息的偏好,并且自动帮助用户做出信息筛选的一个过程。
在这项能够充分满足用户使用需求的机制背后,存在重大隐患。以短视频APP为例,算法自动化决策发挥需要收集用户的浏览信息,算法通过演算得出用户的信息偏好,并且将相关内容推送至用户眼前。用户在使用的过程中会发现,当自己点击了与某个主题相关的视频,用户在接下来使用短视频APP的过程中就会频繁不断地接收到相关主题的视频。这正是算法自动化决策发挥作用的典型现象。
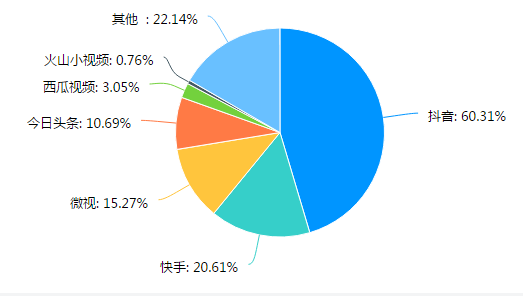
图1 短视频APP使用占比指数
截止目前,在短视频APP中抖音下载量为168亿次,快手下载量为127亿次,微视下载量为14亿次,今日头条下载量为33亿次,西瓜视频下载量为49亿次。由此可见,算法自动决策极大的推动了短视频APP在人们生活中的使用,并根据相关统计人们对于短视频APP的使用时长也在不断增加。如图2,近半数的调查对象使用时长为20分钟到1小时,使用时长在1小时以上的调查对象占三分之一。因为算法自动化决策程序,用户会频繁刷到感兴趣的视频,因此使用时长会大幅延长。但是,这也导致了用户部分隐私信息的泄漏。
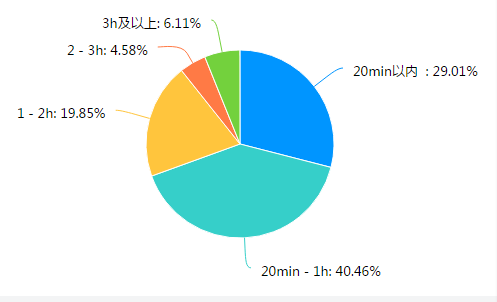
图2 短视频APP的使用时长占比
当下,用户对于隐私信息保护的敏感程度较低,这与中国目前还未出台的相关法律法规有关。国内缺乏对自动化决策下的算法解释权、个人隐私保护权的明确规定,而且在2021年正式施行的《民法典》中的第五章 民事权利第181条规定,“自然人的个人信息受法律保护。任何组织或者个人需要获取他人个人信息的,应当依法取得并确保信息安全,不得非法收集、使用、加工、传输他人个人信息,不得非法买卖、提供或者公开他人个人信息。”可见《民法典》中,涉及的对于个人信息隐私的保护也只是概括性的,针对性不强。这也导致无法对算法使用的各个环节做出明确、合理、完善的治理。
二、算法自动化决策存在的四大问题
人工智能时代,算法的自动化决策是大势所趋,给人们带来数据便利的同时,未知领域会出现的风险恰恰是最无声无息的、也是最危险的。据不完全发现与统计,因算法自动化决策已经出现了“黑箱”、“隐私泄露”、“信息茧房”、“种族歧视”等等问题。
(一)“黑箱”问题
“当社会达到万物互联的普适计算时代后,一切都被数据化,所有的社会运行可能都是通过算法(自动决策系统)在支配。到那时算法(自动决策系统)将成为社会基础设施的一部分。所以算法阳光化是势在必行的,透明化是通往可理解的必要路径。”这是湖南师范大学人工智能道德决策研究所博士,上海玛娜数据科技发展基金会研究员胡晓萌针对“黑箱”问题给出的建议。
“黑箱”问题的出现是人工智能系统发展到一定程度必然会出现的现象,即在设计、开发、运营一个自动决策系统时,由于工作量过于庞大,所以每个技术人员只能负责其中的一个分支,这就意味着很少有人或者说没有人能完全了解、掌控这个算法或者这项技术的发展。“未知”无疑是未来的代名词,但是对于人工智能时代算法的自动化决策来说,“未知”是最可怕的。
(二)对隐私安全造成侵害
“隐私泄露”是一个老生常谈的话题,互联网时代发展到现在很多人都意识到了用户信息的重要性,甚至于很多科技公司的主要业务就是买卖个人信息数据。特别是5G时代的到来,人脸识别技术已然成熟并且广泛运用于各种场景,而在“高风险自动决策系统”使用的所有信息中,生物特征是敏感度和风险系数最高的信息之一,这不得不引起人的注意。“隐私泄露”问题将成为一个巨大的隐患。
这让人想起几年前“深陷Facebook数据丑闻 剑桥分析公司宣布破产”的新闻。引发此次破产的丑闻事件的直接原因是有资料曝光Facebook上超过5000万用户信息数据被泄露,用于在2016年美国总统大选中针对目标受众推送有针对性的信息和竞选广告,其中不乏虚假消息,从而影响了大选结果。
后来General Data Protection Regulation 正式生效,但在生效的第一天,Facebook 就因被指控强迫用户共享个人数据而收到了大量的诉讼,至今也没停止。GDPR 规定互联网企业如果想从用户处收集任何个人数据,需要向用户说明理由并获得直接同意,但是互联网公司获得隐私政策同意的做法却是:要求用户在一个框中打勾。这完全是强迫式的使人同意他们的隐私政策,因为不打勾则完全无法使用该项APP,这在某种方面是违背GDPR规定的。
(三)对信息获取进行限制
近期,随着江苏高考语文作文“同声相应,同气相求”的命题,“信息茧房”话题也甚嚣尘上。“信息茧房”是指人们的信息领域会习惯性地被自己的兴趣所引导,从而将自己的生活桎梏于像蚕茧一般的“茧房”中的现象。这个话题具有一定的争议性,“茧房”本身是人自己的选择,所获取的都是自己喜欢或者感兴趣的信息,但是长此以往会导致网络群体的极化和社会黏性的丧失,人们越来越会只听到自己的回声而听不到更多其他的声音,最终结果就是社会分裂的加剧。
其实,“信息茧房”并不是一个只存在于书面的词汇,它充斥于我们的生活之中,比如人们使用频率十分高的各大短视频APP。以抖音为例,它会在最初期推送点赞率最高的短视频内容,其中风格、类型多种多样,基本能满足人们的各种偏爱和喜好。但在使用一段时间后,这类APP会根据你点赞的内容与频率、关注博主的类型等,给你推送符合特定兴趣爱好的相关内容。这就导致在一段时间的满足之后,你会发现基本只能刷到这一类型的视频,而且它在后期做了优化,不仅推送你感兴趣的内容,还会实时推送最新最热的话题,这就导致某一件事情在某个特殊的时间段里发酵的速度特别快、范围非常广、影响随之就增大了。这既有好的一面,比如在新冠疫情期间,各种正能量的价值观的展现,生活技能的提升,防护工作的普及等等;但是也有其不好的一面,比如谣言传播,负面价值观、负面能量的扩散,攀比、虚假视频对未成年人三观的影响等等。所以,我们要辩证地看待问题,正确地利用工具。
但即使是在后期做了改动,“茧房”现象仍未停止,甚至愈演愈烈,人们都只关注自己所喜欢的内容,活在自己喜欢的环境里,社会黏性和群体极化的问题愈加严重,如果不采取措施加以改善,以后一定会形成极大的社会问题,特别是针对年轻群体的心理问题。
(四)算法自动化决策助推歧视风险
新冠疫情期间,一则美国白人警察对黑人暴力执法的新闻曝光,从而掀起了大规模的游行示威行动,“种族歧视”这个美国的历史遗留问题再一次爆发了强大的破坏力。但是“歧视”问题随着人工智能的升级也迈入了另一个阶梯。
2020年,当地时间4月10日,美国两位民主党参议员布克(Cory Booker)和怀登(Ron Wyden)联合提出了《2019算法问责制法案》(Algorithmic Accountability Act of 2019),试图对人工智能机器学习中的偏见和个人敏感信息使用问题进行规制。
布克在声明中说“必须采取更有力的措施解决’恶性’歧视在科技平台上的使用,虽然有时候这些科技平台是无意的。
以上种种问题虽然令人头疼,但不可否认的是算法自动化决策随着“人工智能”技术的不断进步以及机器学习理论的成熟,已经慢慢渗入到公众生活的方方面面。并且自动化决策过程要更加快速,且具有更高的准确度,给生活带来了便利,也推动了科技的进步。特别是疫情期间,通过算法自动化决策,中国的电商市场向前迈进了巨大的一步,“直播带货”不仅解决了农民、商户的库存积压问题,还活跃了因疫情而格外低迷的消费市场,促进了经济增长。
三、域外相关算法自动化决策的规制借鉴
事物都有两面,如果能够减少算法自动化决策带来的风险性,也将会对人工智能自动化的发展做出巨大的贡献。很明显,在解决问题上,更早使用人工智能的欧美发达国家要更有经验。所以我们可以适当的将目光着眼于国外,参考和借鉴他们解决相关问题的方法和法律。
(一)针对“黑箱”问题--拓扑数据分析
算法黑箱问题一直是阻碍人类推动人工智能算法自动化发展的一只拦路虎。黑箱意味着未知,未知即是恐惧。与之一起诞生的还有同样重要的算法歧视问题,这也是算法不透明化所带来的弊端之一。但近些年来黑箱问题的解决方法国际上却一直没有达成有效的共识。来自美国斯坦福大学的大数据分析公司Ayasdi最近提出,利用拓扑数据分析(TDA)进行可视化分析可能可以解释算法黑箱问题。用拓扑模型通过数据矩阵的行函数的平均值对拓扑结构的节点进行着色,从而查看数据的特征。而近日中科大的潘建伟团队的光量子处理器的成功似乎也证实了拓扑数据分析确实有效。
(二)针对隐私泄露问题--成熟的法律体系
伴随着算法黑箱问题,接踵而来的则是“隐私泄露”和“信息茧房”问题。因为与我们的日常生活息息相关,也是更加需要关注的问题。而比较我国与主要发达国家美国,欧盟的隐私保护,很明显我国还有很多不足的地方。美国1947年的《隐私法案》,1999年的《金融服务现代化法》和2015年的《隐私权案法》,综合性的规范了个人信息利用与隐私保护权的关系。而对于法律未规定的地方则采取行业自律模式,如:建议性行业指引和网络隐私认证计划。也存在着如“美国隐私在线联盟”这种组织督促相关机构对于线上个人隐私的保护,并有相应的解决争议纠纷渠道;欧盟则于1995年颁布《数据保护指令》,并在2012年颁布了《一般数据保护条例》,旨在隐私数据安全监管上明确个人数据的范围与增加数据控制者的义务。虽然这些年国外有关网络隐私泄露的问题频发,但在法律治理上仍能毫不含糊,不得不否认和相对健全的个人隐私保护体系有很大的联系。
(三)针对“信息茧房”问题--仍无法解决
信息茧房现象是这几种问题中最难以解决的。信息茧房,即“用户在海量信息中只选择感兴趣和悦己的主题,从而构成一套‘个人日报’式的信息系统,进而排斥或无视其他观点与内容”。换句话说,只要用户仍旧是一个人,那他就或多或少无法摆脱自我构建信息茧房的冲动。这也是国外目前对信息茧房研究依然没有什么大动静的原因之一。
四、完善我国算法自动化决策相关法律规制的建议
算法在人工智能时代被大面积推广使用以来,使得各领域造成了在不同程度上的风险。但对此我国还并未有相关的立法,且相较于国外,国内对于算法自动化决策规制研究成果较少,相应的治理更为匮乏。由此,我国在未来对算法自动化进行法律规制时,可以分为增设数据管理、算法监督方面入手,要结合我国的现行的法律体系和机构设置的现状,积极探索出一条适合我国的法律治理道路。
(一)增设数据的被遗忘权和更改权
我国人工智能技术的开发与研究较晚,在这方面的立法经验非常缺乏,再加上实际操作中带来的风险并没有欧美国家那样明显,导致我国当前对算法自动化决策的法律治理从总体上来看相对匮乏。
我们的个人信息已经被算法“数字化”,使得我们想要删除或修改信息都有极大的难度。当记忆成为了常态,遗忘就会变得愈加困难。从一定程度上讲,这些对我们来说是限制和束缚。
从立法的紧迫程度上来看,我国当前最适宜的方法应是为民事主体增设被遗忘权和更改权,并且在未来逐步加强对这两种权力的保护。我国在2021年1月1日开始实行的《民法典》中指出:“自然人的个人信息受法律保护”。这个说明我国对民事主体的隐私权有一定程度上的保护。但是光有这一方面,在人工智能时代,对我们的隐私的实质性保护还有待加强。数据的被遗忘权的创立设置使得民事主体有权去决定是否删除网络上所公开过的个人信息,以及是否阻止他人的不合理的利用行为,进一步去界定和控制个人隐私信息的边界。
当今时代大数据技术的飞速发展,使得个人的信息变得极易被挖掘。一旦个人的信息被长期记忆且不能忘记时,那么数字化的记忆便对于使用者而言成为了一种束缚。所以要增设被遗忘权可及时更改算法自动化的记忆,使得个体的信息不被数据所裹挟,从而可以恢复个体信息的灵活性,有利于个体信息的自我塑造。
(二)完善侵权责任机制
网络上的经营者想要“杀熟”,其前提需要掌握使用者的个人信息特征,但收集、使用这些信息的过程中很有可能就会损害使用者的个人信息的权利。《消费者权益保护法》第十四条中规定了“享有个人信息依法得到保护的权利”,第二十九条中规定了“经营者消费、使用消费者个人信息”的义务,第五十条规定了经营者“侵害消费者个人信息依法得到保护的权利”的民事责任。这些法律条文搭建起了使用者个人信息权利保护的特别框架。
根据侵权法的内容,“杀熟”的网络经营者承担侵害使用者个人信息权利的侵权责任,需要存在过错、对使用者造成了损害,且二者之间应存在着因果关系。《消费者权益保护法》其实并没有禁止网络经营者收集和使用使用者的信息。但是如果经营者在事前获得了使用者的“知情同意”,并且履行了保密的义务,其收集和使用使用者的信息就符合法律规定,就不存在违法的过错。网络上的经营者通过“知情同意”收集的使用者个人信息,对使用者进行“信息裹挟”,使使用者处于“数据监控下的不安”,要将其认定为侵权法下的损害难度较大。经营者未表现违法的过错,而使用者的损害又难以认定,算法自动化决策带来的“大数据杀熟”的侵权法解决路径陷入了困境。
想要对这一侵权法解决路径有所突破,应从侵权法的完善入手,去完善法律法规针对经营者收集使用使用者个人信息的限制,并明确使用者个人信息的范围。
(三)事前管控和事后追责相并重
事前管控和事后追责是根据“大数据杀熟”的特点而提出的法律规制的相关建议。关于事前管控,应当保护使用者的个人信息,但同时也要明确经营者收集使用者信息的范围。事前管控到位,就可以对经营者滥用使用者的信息进行有效的控制。关于事后追责,很多使用者会不愿意或者说是难以获得司法途径的救济。这样也可以避免相关部门介入并不熟悉的领域。综上所述,我们应该将事前管控与事后追责相并重来对算法自动化进行法律规制。
五、结语
小组成员们以短视频APP为探索切入点,针对研究方向,整理出了以短视频APP为例的算法自动化在人群中的普适性数据,肯定了研究人工智能时代算法自动化风险问题的必要性,初步总结出了算法自动化现存的四大问题——“黑箱问题”、“隐私泄露”、“信息茧房”、“算法歧视”,并且通过对比国外自动化决策相关问题的法律治理实例,小组成员们综合我国法律现状,为算法自动化决策法律规制提出了“增设数据的被遗忘权和更改权”和“完善侵权责任机制”这两点建议,为之后深入研究奠定了相关理论和实践基础。
然而在项目的研究过程中,我们也发现了很多现阶段无法解决的问题。例如,在2021年正式施行的《民法典》中,极度缺乏对于用户信息隐私的保护条例以及后续处理办法;现阶段的信息技术手段,无法从根源上解决现存的四大问题等等。这些法律上的空白,我们希望在不远的将来都可以得到重视和补充。
参考文献:
[1]郑智航,徐昭曦.大数据时代算法歧视的法律规制与司法审查——以美国法律实践为例[J].比较法研究,2019(04):111-122.
[2]孙建丽.算法自动化决策风险的法律规制研究[J].法治研究,2019(04):108-117.
[3]廖建凯.“大数据杀熟”法律规制的困境与出路——从消费者的权利保护到经营者算法权力治理[J].西南政法大学学报,2020,22(01):70-82.
[4]高培培.构筑遏制大数据“杀熟”的法律屏障[J].人民论坛,2019(36):130-131.
[5]张建文,潘林青.人工智能法律治理的“修昔底德困局”及其破解[J].科技与法律,2019(05):43-52.
[6]贾章范.法经济学视角下算法解释请求权的制度构建[J].黑龙江省政法管理干部学院学报,2018(04):74-78.
[7]胡洪森. “大数据杀熟”必将搬起石头砸自己的脚[N]. 北京日报,2019-10-16(014).
[8]沈亮亮.算法在市场竞争中的应用与法律难题——从大数据杀熟谈起[J].太原学院学报(社会科学版),2019,20(03):26-31.
作者简介:
薛凯心,2001年1月29日出生,汉族,籍贯吉林省通辽市,南京审计大学,法学(法务金融方向)

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



