嵊州市前沿电子科技有限公司 浙江省绍兴嵊州市 312400
摘要
随着人们越来越多地意识到使用语音交换接口的价值,他们开始尝试使用语音技术,并在许多领域取得了可喜的成果。语音技术已经从锦上添花变成了为用户提供方便的重要特征和内涵,也成为衡量电子电器产品智能化程度的重要指标。语音技术发展的目的是让人们充分享受人机界面中信息交流的亲切感和人性化便利。目前,在国内外,语音技术的应用已经相当成熟地进入了日常用品和工业产品的许多领域。本文分析了互联网语音智能控制系统;分为四部分分析;第一部分引言;第二部分系统的整体设计方案;第三部分系统硬件设计;第四部分系统软件设计。
关键词:互联网;语音智能;系统
20世纪80年代初,随着大量采用电子技术的家用电器面市,家居系统电子化(HE,Homen Electronics),智能化越来越多。然而当今人们对日常设备的智能化控制要求越来越高,从原来的复杂化到简单话,在由简单化到傻瓜化,但是现在人们还是不满足,他们还想要更简单的更方便的更智能的方法来控制自己拥有的设备,这就是语音控制系统为什么会在现代社会如此流行,如此受到大家的欢迎,让语音控制系统成为当今最前沿的民用控制技术。
在语音识别的系统里,其对原始语音信号进行预处理是必要的,那么这样就可以保证其系统获得一个比较理想的处理对象。语音信号的预处理主要包括:预加权滤、波抗混滤波及端点检测等内容。
2.1.1抗混滤波与预加权滤波
根据研究,从确保一定的可识别性的角度来看,只需要保留3.5千赫以下的语音信号。因此,为了消除语音信号中宽带随机噪声的叠加,我们需要在系统前端进行反混频滤波,以分离出该范围内的语音信号的频谱,然后对其进行采样,并对其进行离散时域语音信号。
根据采样定理,如果模拟信号的频谱带宽有限,采样频率大于或等于m4,得到的信号可以很好地代表模拟信号,或者从采样信号中恢复出原始的初始信号样本。在实际应用中,系统通常选择8千赫的采样频率。然而,语音信号本身包含高于4千赫的频率成分。即使语音信号的频谱能量主要集中在低频带,这是由环境的宽带随机噪声叠加的,语音信号在采样前也将包含高于4kHz的频率分量。这样,信号频谱的能量可以主要集中在低频带,并且随着环境中宽带随机噪声的叠加,语音信号将总是在采样之前被收集。因此,为了防止混叠失真和噪声干扰,有必要在采样前通过低通滤波器进行滤波。这称为反走样过滤或反走样过滤。如果声音从嘴唇发出,它将衰减6dB/oct,这表明如果频率加倍,声音信号功率将减少1/4,或者信号幅度将减少1/16111。因此,为了弥补这一损失,系统需要预加权滤波。预加权滤波可以通过采样前的模拟滤波或采样后的数字滤波来实现。
2.1.2端点检测
端点检测的目的是在输入信号中找到所需的语音信号。语音识别的关键问题是语音端点检测的准确性,以及为系统提供最佳语音模式的准确性有多高。最好意味着这种语音模式可以带来最好的识别率。通过与说话人无关的语音识别实验,说明了端点检测的准确性对识别率的影响。第一步是人工检测端点,识别率为93%;在第二步中,当等待识别的语音段保持不变时,端点向前和向后移动。结果,当端点和原始端点之间的差值为60毫秒时,识别率降低了3%。随着端点的进一步偏离,识别率有所下降。当端点之间的差异为150毫秒时,识别率下降了近30%。这充分证明了端点检测的重要性。
环境噪声和系统输入噪声相对较小,以确保系统输入信噪比较高
如果输入信号具有短能量,则可以将语音段与噪声区分开。
此外,由于清音、弱摩擦音、弱爆破音和鼻音的短期平均通过率几次超过背景噪声的平均通过率,所以语音片段的短期平均通过率也可以用于端点检测。以下是终点检测方法中短期平均振幅和短期平均过零率的介绍。
1)短期平均振幅
在短时能量端点检测方法中,需要计算语音信号的短时能量,因为短时能量的计算涉及平方运算,而平方运算必须放大不同幅度的相邻采样值之间的差值
幅度差,用短期平均幅度来表示语音能量可以在一定程度上克服这一缺点。
通常其采用的移动窗为:矩形窗和汉明窗,它们定义分别为:

语音信号就是不平稳随机过程,其特性是会随时间变化的,但是这种变化很缓慢的。基于此,可以将语音信号分为一些相继短段进行处理。短时平均
幅度包络可以按帧频率进行取样。以短时平均的幅度为特征起止点的算法:根
据其发音刚开始前已知为“静”态连续数帧内数据(帧长为loms),计算能
量的阀值ITL及ITU。
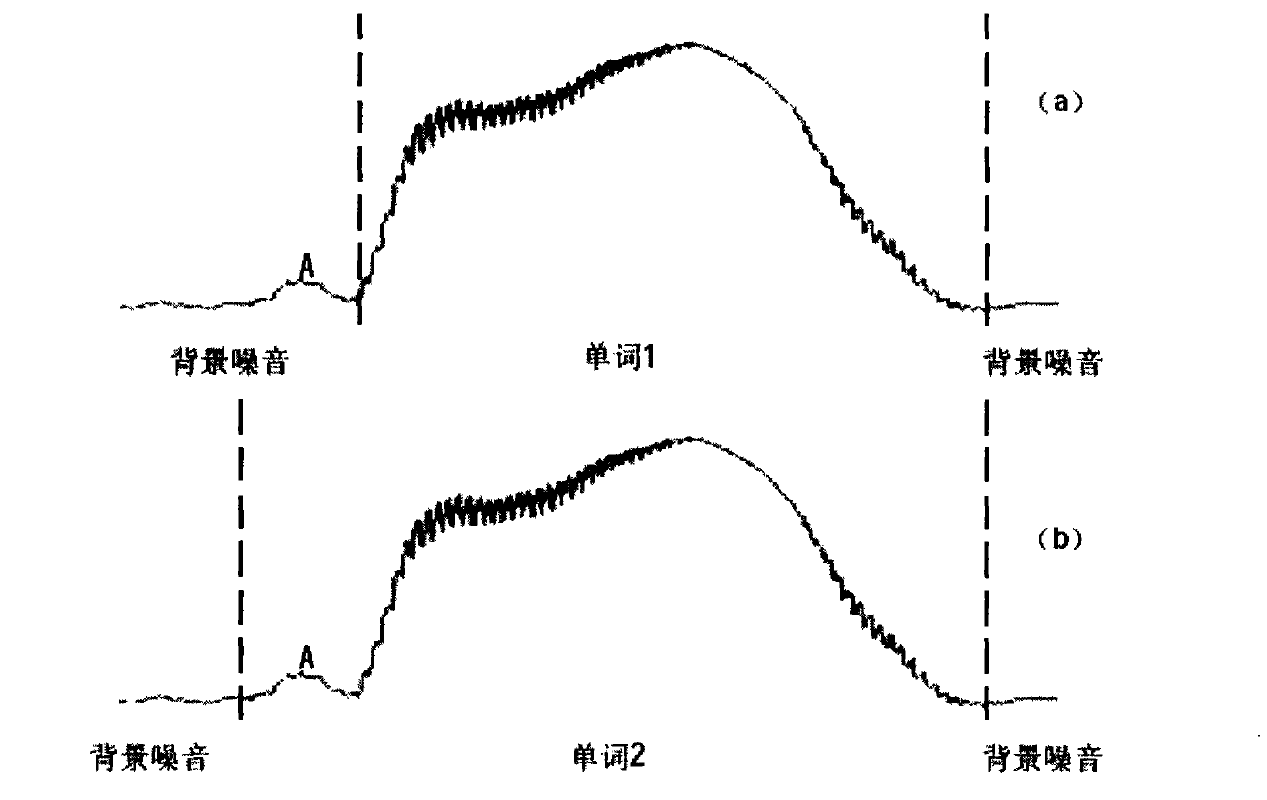
由此便可进行起止点判别:先根据ITU、ITL确定一个初始的起点如Ni位口图2.1所示单词1的A点,把它确定为最先的升到平均幅度帧,并随着时间的推移,帧幅度会在升到ITU之前并又下降到ITL之下,所以N,不作为初始起点,而改到下一个升到ITL的点为Ni,以此类推,直至取到真正的初始起点为止。
2)短时平均过零率
随着离散时间信号的相邻两个取样值有不同的符号时,就会出现“过零”的现象,其单位时间过零次数叫做“过零率”。例如离散语音信号包络是窄带信号,那么会利用过零率比较准确地度量此窄带信号频率;在宽带信号情况下,过零率只是大概反映信号频谱的特性。
语音信号其不但是宽带的信号,而且还是时变的信号,其频谱特性是会随时间变化的,所以短时的平均过零率,实际上就是描述时变的频谱一种最简单的方法。
短时的平均过零率计算方法是:首先用一个移动窗w(n一m)选取位于n时刻语音段,并且计算出该语音段的过零总数,除以该短时段的长度(即窗的宽度)。并设采用矩形窗,窗的宽度为N,这时,短时的平均过零率即可用下式计算:
该算法以其短期平均过零速率为特征的起点和终点,是:根据发音前被称为“静态”的连续帧及其数据计算过零速率IZCT的封闭值。
可以执行终点判别:以根据CT确定初始起点lN,CT被定义为首先上升到平均过零速率的阈值的帧数。随着时间的推移,过零速率下降到IZCT以下,此时的从属点作为语音段的结束点。
根据上述方法,N2不能被设置为终点,并且应该从它向后查看几个帧,以检查它是否是zcR高点,即,在NI 分灿25的每个帧中是否有其他zcR zIcT。如果有三个以上这样的帧,那么端点将被移动到满足ZCR IZCT条件的最后一个帧号。
任何识别器的输入数据都包含相关信息和不相关信息。提取特征参数是尽可能丢弃不相关信息,并以严格合理的形式描述相关信息的过程。语音信号不仅包含反映单词的信息,还包含反映说话人不稳定性的信息。在识别系统中,在选择特征参数时,应尽可能反映前一种信息,减少后一种信息的影响。常用的语音信号特征参数包括:时域参数,如:短期平均能量或振幅;频域参数,如:线性预测系数及其倒谱、清音/浊音符号、基因频率、短时傅立叶变化、共振峰值等。
时域参数具有计算量小的优点,这对于区分语音段和清音段以及清音/浊音段更为方便和有效。然而,由于人耳对声音的频域特性很敏感,时域参数不能很好地反映这一特性。
特征参数提取是从语音信号中提取(或测量)具有代表性的合适的特征参数,同时进行合适的数据压缩。
线性预测分析技术是目前广泛使用的特征参数提取技术。线性预测系数的倒谱特征向量反映了语音全极点模型平滑谱的对数幅度,计算简单,在语音识别中有很好的效果。因此,许多成功的应用系统都是基于LPC倒谱技术来提取特征参数的。
复位电路扮演着重要的角色。当单片机接入电源或电源本身处于低电压状态时,复位电路将起到复位单片机存储器的作用,使所有参数回到初始位置,用于消除各种情况下的程序紊乱。
单片机的复位电路有两种形式:上电复位和手动复位。如果RST端的高电平直接通电并立即产生高电平,它将被通电并重置;如果通过按钮产生高电平复位信号,则称为手动复位。上电复位通过电容充电实现,手动复位通过开关SB1实现。当RST从高电平变为低电平时,复位结束,中央处理器从初始状态开始工作。中央处理器的初始状态是所有引脚(除了接地引脚)都用高电平上电。
时钟电路由晶振元件与单片机内部电路组成,产生的振荡频率为单片机提供时钟信号,供单片机信号定时和计时。
在AT89C51单片机内部有一个高增益反相放大器,其输入端引脚为XTAL1,其输出端为XTAL2。只要在两引脚之间跨接晶体振荡器和微调电容C1、C2,就可以构成一个稳定的自激振荡器,如图3.4所示。电容C1和C2取33pf左右;晶振的频率范围是1.2~12MHz。晶振频率越高,系统的时钟频率也就越高,单片机的运行速度也就越快。在通常情况下,使用振荡频率为6MHz或12MHz的晶振,如果系统中使用了单片机的串行口通信,则一般使用频率为11.0592MHz的晶振,因为晶振频率为11.0592MHz可以使计算出的T1初值为整数且实际波特率不变误差为0。表3.1列出了串行方式2在不同晶振时的常用波特率和误差。而在本次设计中采用的是频率为11.0592MHz的晶振。
直流变压器提供的电源,波动比较大。因而系统采用稳压芯片7805及电容组成的系统的电源系统,将9-12V的直流电,稳定为系统需要的5V直流电。为了保证系统的模拟部分不受数字部分的影响,在电源系统把模拟电源、数字电源和模拟地、数字地分开。
键盘是通过中断的方式来控制系统的,系统初始化完成后,进入等待状态,然后根据键盘指令执行要求的功能,例如:开始按键录音,再次按键停止;或者按住键录音,松开停止。
系统输入是通过一个驻体话筒把语音信号转化成模拟电信号。由于语音信号比较弱,给处理带来困难,也影响识别结果。系统设计了一个二级模拟放大图,来放大话筒的输出。
抗混滤波器的作用和参数设计已经在本文前面的章节中进行了详细的说明。本系统的抗混滤波器是通过运放和电阻、电容设计的一个4阶巴特沃思型低通模拟滤波器。
在这儿我们会用的是SPCE061的特定语者辨识SD(Speaker Dependent),SD就是语音样板经过单个人训练,也只能由识别训练某人的语音命令,从而他人的命令识别率比较低或几乎不可能识别。
可以使用计算机来录音,选取录音效果一般的MIC较好,由于小车跑动时会受环境的影响,效果较一般的MIC录制的音更能逼近凌阳单片机上的MIC所录制。录制语音可能为:“yeah”,“烦不烦”,“前进”,“倒退”,“拐一拐”。分开来保存名为:yeah.48k、qj.48k、dt.48k zg.48k、yg.48k.
语音录制的时候,应注意录制属性设置,最好选择8Khz, 16位,单声道。语音录制好之后,保存格式应为“.wav”,使用凌阳单片机光盘中目录“\TOOLS\s480\”下的工具用来进行语音压缩后放在程序目录“\voice”的下边,接着修改配置文件“Makefile”中的OBJFILES值和对应的相关语音文件的目录地址值和“clean”的值 ,并且配置值顺序必须要对应于语音训练的过程。
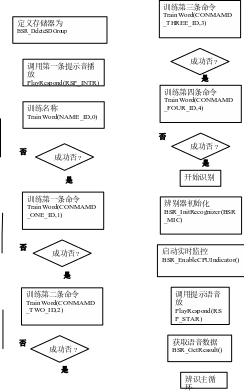
这个程序模块包括于三个部分:训练样本、识别、语音提示。具体的程序见主程序。如下图整体框图。

语音辨识整体框图
在这程序中我们要通过五条语句的训练从而演示特定人连续音来识别,其中第一条语句是触发名称。另外四条则是命令,训练完毕开始后辨识应该识别出触发名称后,再开始发布命令,就会听到自己设置的应答,
众所周知,语音识别难处在硬件资源是相对有限的(相对与PC机而言),还要实现大量数据处理的语音识别算法。另外特别的,SPCE061A自带2K字的RAM,这样小容量的RAM空间是怎么存储数据量较大的语音命令,是很值得探讨的问题。
再时域分析之中,语音信号是缓慢时变的信号,且在某一段时间中,如10ms~20ms,语音信号的特征不变,由于这些短段是有固定特性,段间有一定的重叠,组合成一段语音后,常把语音信号分成的小段(称为“帧”)当作为提取语音信号特性的单元,这中的方法叫做为“短时”处理法。
当以8K/S的速率采集信号的时候,要是以20ms为帧周期,接着加上12ms的帧移,帧长32ms,即每帧包含256个语音采集点,一个帧的特性参数占着1个字RAM,那样的话存储一条2S长的语音命令信号占用。
当以2s/20ms*1=100字,与直接存储采样的语音数据会比较更加能节省嵌入式系统有限的硬件资源。当有外界噪音的干扰下,对语音起止点的判别非常之重要,要是声音指令信号提取不恰当,则所得到的声音指令信号和发出的指令就会有很大的不同,不但会延迟语音识别的时效性,而且会降低对
语音信号的识别率。对语音信号的提取,主要是确定音头和音尾的位置,即端点识别。最常用的方法有短时能量和过零率等几种。
短时能量表示了语音信号的幅度,其定义式为:
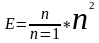 (公式3)
(公式3)
语音辨识具体流程图
短时平均过零率为语音信号穿越零电平的次数,接着就是短时信号的频率,其定义如下:
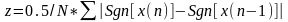 (公式4)
(公式4)
式中的N为一帧语音的采集点数。
对于语音的采集中,计算当前一帧或者多帧数据的能量或过零率数值,要是大于预先设定的阈值的时候,则认为找到了语音命令的起始点,那么结束点的确定方法与之差不多。
当截取音头音尾间的信号并分帧之后,可以用帧为单位进行特征参数的提取,例如线性预测倒谱系数法。选择适合的特征参数,对于语音样板参数经过动态时间弯折算法匹配,就能算出出相应的识别结果。
本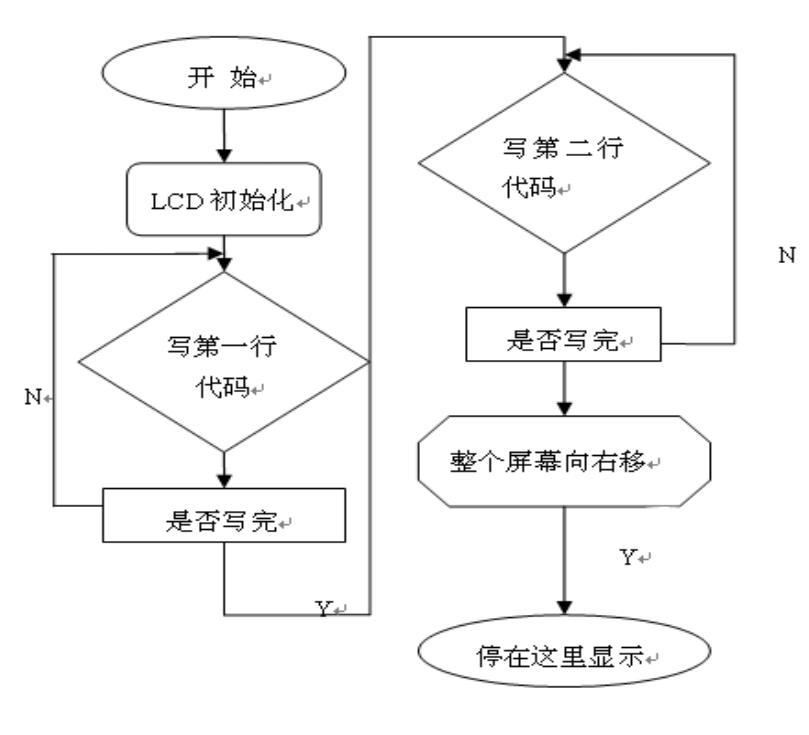
课题的程序设计可分为两大块,分别是:
IIC协议;
LCD显示;
程序总体框图如图所示
在不断发展的现代化进程世界,未来会一步一步朝着智能化方向进行下去。智能是指在某个设定的模式下,或者某个环境中,基本不用人为操作,机器会代替你会完成各种各样的任务和操作,可扩展到各个领域里使用。在最近这些年,各种新技术、黑科技被人们研究发现,并应用到生活中,而关于语音交互则是其中非常火非常热门的项目,并在将来也会是许多人热衷于去发展的一项研究。语音交互技术作为一门综合类复杂性学科,其中包含了各领域的尖端技术,现在正逐步成为一种重要技术,它承载着沟通人与机器的桥梁作用。用户通过某种方式语言对某个机器输入信息,机器终端对用户语音进行意图的理解判断,并执行用户命令使之能满足使用者下达的要求。在玩具市场,带语音交互的智能玩具已成为玩具市场的主流;在消费电子市场,现在如日中天的苹果手机,其语音交互系统SIRI的出现给人们生活带来更多的体验及便利,它能结合周围环境对机器进行控制,通过语音来完成复杂的人工操作,省去了不少麻烦,给我们带来了诸多方便。
参考文献
[1]李泽山,郭改枝. 基于树莓派和Ardunio的WiFi远程控制智能家居系统设计[J]. 现代电子技术,2019,42(24):167-171+175.
[2]. 语音风潮来袭 “智能电视”与“互联网电视”彻底划清界限[J]. 消费电子,2012(04):80.
[3]喻国明,杨名宜. 平台型智能媒介的机制构建与评估方法——以智能音箱为例[J]. 新疆师范大学学报(哲学社会科学版),2019,40(02):120-126.
[4]陆刚. 智能家居的网络控制技术探密[J]. 办公自动化,2016,21(03):37-44.
[5]周德建. 实现常规洗衣机的远程云智能控制[J]. 科技与企业,2013(04):84-85.
[6]宋威,黄进,尹航,庞志远,梁鹏程. 基于WIFI物联网的家电智能控制系统信息控制端的研究[J]. 信息通信,2013(01):199-200.
[7]邓何勤,陈晔,王伟. 移动互联网流量经营策略研究[J]. 通信与信息技术,2013(01):51-53.
[8]苏安辉. 基于智能化背景的校园广播系统升级设计[J]. 岳阳职业技术学院学报,2016,31(05):87-89.
[9]陆刚. 智能家居的网络控制技术探密[J]. 电气工程应用,2017(02):23-32.
黄军,1988年1月,男,汉,浙江永康市,本科

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



