西南民族大学计算机科学与技术学院
摘 要:近年来,大数据、云计算、人工智能等新技术的迅速发展,数据量也急速增长。对于多模数据的应用和海量数据的处理已经成为研究人员最关注的话题之一。而神经学习的出现,给处理多模和海量数据带来了新的方向。深度学习构建的神经网络可以很好的处理非结构化的数据,给推荐算法的发展指明了道路。文章搭建了一种基于深度神经网络的多模信息推荐算法模型。实验结果表明,该模型能够有较好的推荐效果。
关键词:推荐模型;深度神经网络;多模信息
1、引言
近年来,大数据、云计算、人工智能等新技术的快速发展,网络数据的指数增长和多样化在各领域的发展带来了新的机遇和危机。一方面,更有价值的多模数据信息Error: Reference source not found能给推荐带来更全面的结果;另一方面,由于用户的需求越来越广,面对稀疏性和冷启动问题,传统的协同过滤推荐算法不能很好地适应用户需求。因此,寻找到有效的新技术来取代传统的技术是一件迫在眉睫的事。
推荐系统通过收集和分析用户的数据来寻找用户的兴趣和行为模式,进而从大量繁杂的数据中找到符合用户的项目,将其推荐给用户,节约了用户筛选信息的时间,有效的提高了信息的利用[1]。本文利用深度学习的知识[2],搭建了一种基于深度神经网络的多模信息推荐算法模型,此模型在本文中主要是针对电影进行推荐,结合了用户和电影本身的各种信息,利用各种数据处理的手段,将信息转化为稠密矩阵输入模型中,最后证明模型的有效性。
2、相关技术介绍
2.1 传统推荐算法
传统的推荐算法主要有协同过滤算法和基于内容的推荐算法两大类[3]Error: Reference source not found。第一类是基于用户(user-based)的协同过滤,它基于的原理是给兴趣爱好相近的用户推荐相似的物品。第二类是基于物品(item-based)的协同过滤,它基于的原理是用户感兴趣的物品有相似的特征。基于内容的推荐算法的核心思想是 用户过去的历史记录给用户推荐没有看过的但在内容上与他感兴趣的物品相似度高的物品。利用用户的历史行为数据,为用户推荐和他之前感兴趣的物品相似的物品。
2.2 卷积神经网络
在21世纪后,深度学习出现收到了广泛的关注,理论方面和硬件技术方面的快速发展,同时也提升了人们对卷积神经网络发展的重视,因此卷积神经网络在计算机视觉、自然语言处理等方面得到了广泛的应用。卷积神经网络是受生物的视知觉(visual perception)机制启发研发出来的一种具有深度结构的前馈神经网络Error: Reference source not found。它在传统神经网络的基础上增加了卷积层和池化层,具有权值共享和局部连接的特点,且采用了前向后向传导的方式,使得输出值的计算和参数的调整更加方便。卷积神经网络神经元与一般神经元之间的全连接方式不同,它采用的是部分连接方式,部分连接方式大大降低了参数数量和模型的复杂度,具有十分优良的泛化能力[4]Error: Reference source not found。
3、推荐算法模型设计
3.1整体模型设计
为了用户非文本信息、电影非文本信息,电影文本信息三大模块。以下分别介
绍各模块的设计原理和构成。
3.2 用户非文本信息
最左边用户非文本信息是用来进行用户特征提取的,先将用户四个预处理后的UserID、Gender、Age、Occupation向量,通过嵌入操作表示为对应的特征向量,进而输入到神经网络进行两次全连接操作后输出用户特征矩阵。
3.3 电影非文本信息
中间部分的电影非文本信息处理是,先对电影海报用VGG16进行特征提取,计算目标海报的相似度,再根据电影海报蕴含着电影风格信息的原理,将相似度高的海报的Genres提取出来,用来填充目标海报的不完善Genres的信息;在补充好电影Genres数据后,进行电影特征提取,先将电影其中两个预处理后的MovieID、Genres向量,通过嵌入操作表示为对应的特征向量,输入一个全连接层中。
其中电影海报是从IMBD上爬取下来的。由于Vgg16 卷积神经网络要求输入的图片的格式为224×224像素,将 IMBD 数据库获取到的182×268像素的电影海报图片进行处理。接着 Vgg16 卷积神经网络对输入的图像进行卷积处理,本文可以通过ImageNet数据集训练得到的卷积核,来有效提取图像的特征。经过Vgg16卷积神经网络进行特征提取,每一个输入会形成一个512×7×7的输出,输出即提取到的电影海报的特征数据,将这个输出处理为一维向量形式。每个电影海报的特征记录下来,可以计算电影海报的相似度。计算公式如下.

其中![]() 是用户u对项目i的评分,
是用户u对项目i的评分,
![]() 使用户u对项目j的评分。
使用户u对项目j的评分。
再将推荐目标电影相似度最大的Top-k,将他们对应的电影类别标签提取出来,对信息不完全的电影类别信息进行补充。
3.4 电影文本信息
先使用Word2vec对电影文本信息Title进行预处理得到Title向量,通过文本卷积神经网络表示为对应的Title特征向量,在与中间得到MovieID特征与Genres特征求和后全连接的向量再进行一次全连接操作输出电影特征矩阵。
最后的得到的用户特征矩阵和电影特征矩阵通过模型顶端的全连接层,将他们映射到同一空间,得到用户预测评分矩阵,使用均方误差(MSE)来检测它和真实评分之间的偏差并进行回归运算优化损失。
4、实验
4.1 实验数据和评判指标
本文采用的是MovieLens的数据集中的ml-1M,其中的movie.csv、rating.csv、users.csv分别包涵了电影信息、用户电影评分信息、用户信息。
在本模型中使用的是评估方法是平均绝对误差MAE,该方法简单并且能够很好地体现出模型效果的好坏,计算公式如下:
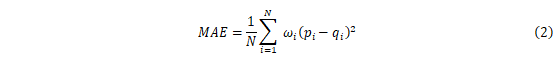
其中,pi是电影i的预测评分,qi是电影i的实际评分,ω是权重,N是评分的总个数。如果MAE的值越小,则表示推荐结果的准确性越高。
4.2 实验流程
首先确定训练环境,本文使用Tensorflow框架,并配合CPU训练 ,接下来建立模型的训练,测试,并引入优化器训练。之后,根据设定Epoch的和其他参数,然后开始训练模型和测试。每次训练完成之后都要进行测试,当循环得到的训练结果在测试时表现的效果符合或者超出预期则可以停止循环训练,并且保存该时刻模型的各项参数值。
本文中模型的损失函数最终稳定 1.0附近,反映了模型具有比较优异的推荐效果。
参考文献:
基金项目:西南民族大学研究生创新型科研项目;项目编号:CX2020SP65

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



